Analyzing suspicious URLs on an individual basis can be tricky, but when you’re facing a large volume of potentially malicious URLs then other approaches that leverage automation (like machine learning) become critical.
At Intezer, we recently launched a URL scanning feature that will allow detecting phishing/malicious URLs. To do so, we have multiple integrations with services such as URLscan and APIVoid, and additionally, we are adding in-house built tools. We built our URL scanner to be capable of both automated use cases (adding a deeper layer of automated triage and analysis into phishing investigation pipelines with thousands of suspicious URLs), as well as “manual” analysis of individual URLs discovered during investigations.
This blog is the second of a URL analysis 101 series. In the previous part, we discussed how people with malicious intent can modify URLs to leverage human and browser weaknesses to successfully “phish” people clicking on URLs. In this part, we are going to discuss automatic detection for URLs and some of the reasoning behind the various methods. We are going to emphasize the popular use of machine learning for such a task.
Motivation for Using Machine Learning
To understand the motivation behind this blog, we first must understand the general methods of automatic URL detection.
In general two methods are discussed:
- List-based – Blocklisting or allowlisting of websites, examples for these kinds of lists are:
- URLHaus
- Phishstats
- Alexa rank (a high rank will give credibility to the trustworthiness of the website)
- Machine learning-based – Usage of labeled URLs and extracted features from the URLs to train ML models.
Pros And Cons of List-Methods and Machine Learning Methods
List-based methods
- Pros: These methods are very precise, meaning if a URL is included in a blocklist it is malicious with a very high probability and will generate a very low rate of false positives.
- Cons: The problem with list-based methods is that they will not be able to detect new phishing websites, because any URL that is not in the list will not be identified.
Machine learning-based methods
- Pros: ML methods are able to detect new malicious URLs based on the URLs and/or web page characteristics.
- Cons: ML methods will generally generate more false positives than list-based methods.
Machine Learning: A Small Intro
Don’t panic! No maths and not very complicated material in this section.
Please note that we are not going to give a full machine learning solution to the problem but merely give an intuition of a machine learning approach.
In order for our machine learning model to learn the differences between phishing and trusted URLs, you need to be able to provide it with labeled data, in our case, “trusted”/“phishing” for each URL.
When we have labeled data we call the machine learning process supervised as opposed to unsupervised learning where we get a dataset that does not have the labels which we need to learn.
What Information Can We Extract From A URL
Usually we refer to information or a characteristic about something we need to learn from in machine learning as features. The main categories of interesting features we can extract, from a URL, are the following:
- Lexical features – These are features that are based on the text of the URL itself, a couple of examples include URL length (usually to do some URL manipulation you need to add more text to the URL), the number of digits in the hostname (in legit URLs digits are rarer), the number of subdomains, entropy, the number of special characters like “@” and many more.
- Domain features – These are features that are related to the website registration based on the whois information and can include: the number of days since the registration or expiration of the domain of the website, and more.
- Webpage features – It is also possible to extract features from the webpage you are directed to, however, this requires getting the full web page and is kind of a heavy process.Features from the webpage could include the number of links, images or HTML titles, and others.
For simplicity’s sake: let’s take URL length (number of characters) as a first feature and the number of digits in the URL as a second feature and look at some examples:

So let’s take a look at the first phishing URL and the first trusted URL in the above example.
- Phishing URL – http://postsfb-hg36wq99.novitium.ca/profile.html?countUser=92f5f58259eedaddcef524ed5d2040eb
So here we have URL length 91, the number of digits is 20 and it is phishing (notice the ‘fb’ inside of the URL which wants to make us believe it’s Facebook).
So let’s turn this into a numeric vector!
[91, 20]
Amazing isn’t it? The first value if the vector represents the URL length and the second represents the number of digits inside the URL.
Let’s look at a second example.
- Trusted URL – http://distritoforestal.es/ which gives us this numerical vector => [27, 0]
Now that we have these numeric vectors, let’s plot a couple of these URLs using URL length and the number of digits inside the URL:
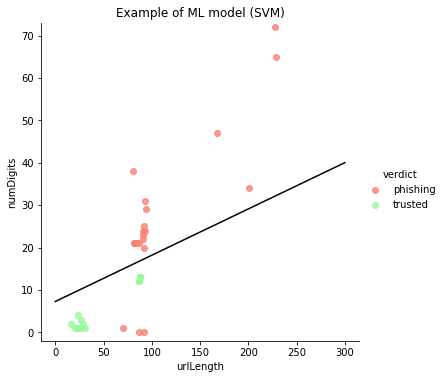
In this plot, we see 40 points in total representing 20 for each category. The Y-axis represents the number of digits and the X-axis represents the URL length.
The main reason we chose to use only two features is that they are easily plottable and can give a good visual sense of how we could mathematically separate the groups.
In this process, we actually took the text of the URL, transformed it into a numeric vector and we plotted them on a 2-dimensional plane. The line you see on the plot was learned by a Machine Learning algorithm called SVM or Supplied Vector Machines.
Using this very simple model we can now divide the plane as you can see in the visualization, every new URL that will arrive in the lower part below the classification line will be classified as a trusted URL and above the classification, the URL will be classified as phishing.
For example, a new URL getting to this classifier with lengths 50 and 20 digits will be classified as a phishing URL and a URL with length 50 and less than 5 digits will be classified as trusted.
Another important point is we can notice that using only two features, the length and the number of digits will create some false negatives as 3 phishing URLs are incorrectly classified as trusted URLs.
Automating URL Analysis
Large organizations are increasingly looking for automation to scale high-volume phishing investigation pipelines, including methods like machine learning for URL detection. In this part of the blog, we discussed how machine learning can be used for automatic URL detection. We discussed the advantages and disadvantages of using machine learning and list-based detection methods.
We hope that you enjoyed reading this blog and feel free to contact us for any further questions regarding our products and our URL analysis tools.