In our previous post, we went through the concept of symbols and their functionality. In this post we will introduce the concept of relocations and its relationship with symbols.
By the end of this post, the reader will be ready to understand more advanced concepts, such as dynamic linking, which we will cover in depth in our next post.
1. Defining ELF Relocations
In our previous post we covered what it means for a file to have symbolic information - when a file contains symbolic information it means that it contains source code exported metadata, in order to better interpret the generated machine code.
However, symbolic information by itself is useless. Symbolic references and symbolic definitions have to be connected with one another. The mechanism of connecting symbolic references with their correspondent symbolic definitions is what is know as Relocations.
Let’s say we have a program that adds the value of two global variables together. In order for those variables to be successfully referenced in our program, their addresses within the process virtual address space have to be resolved. As an additional example, If our program is calling a function from an external dependency, the address of that function will also have to be computed prior to transferring control of execution to it. These two scenarios are examples of where relocations have to be applied.
During the compilation process of a program there is a specific stage were relocatable objects are generated. These relocatable objects contain all the information required to map symbolic references to its corresponding definitions. Populating symbolic references on symbolic definitions takes place during the linking phase of the compilation process.

Figure1: compilation process
There are different types of relocatable files:
- Generic object files (*.o).
- Kernel object files (*.ko).
- Shared object files (*.so).
Generic object files are the ones that are used for static linking, they are only relevant in the compilation process and essentially, any given symbolic definition will become part of the main executable being generated.
Obviously, this linking type has its benefits and flaws. On the benefits side, we should note that there is no need to rely on external dependencies to make the main executable work across different hosts. On the other hand, statically linked executables can become particularly large, since all needed dependencies of a given program will become part of the generated binary itself as previously mentioned.
Furthermore, another type of relocatable object are Kernel objects. These type of objects support being loaded to the kernel as a module (commonly known as LKM), without the need to restart the system. We will talk about Loadable Kernel Modules more thoroughly in future posts.
There are also shared objects. These type of relocatable files support being linked on runtime, and they may be shared across different processes.
Consequently, relocations of dynamic dependencies have to be done at runtime. This process is known as Dynamic Linking.
The reason these relocations take place at runtime, is that as opposed to static linking, the symbolic definitions do not exist within the main binary’s context, but within external shared objects. These dynamic references will not be populated until the correspondent external dependencies are loaded into memory.
Image bases of dynamically linked dependencies are not deterministic, since they will differ even between different process instances of the same executable.
Furthermore, as an interesting fact, dynamic dependencies in Linux systems do not have preferred based image bases, as is the case with Windows systems - Process A libc.so will not be mapped at the same address as process B libc.so.
2. Relocation entries
Relocation information is held in relocatable entries, located in specific relocation sections within an ELF object. These entries are implemented in the form of structures. There are two different Relocation entry structures: Elfxx_Rel and Elfxx_Rela:
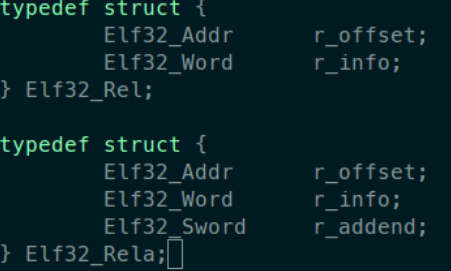
As seen in the figure above, the only difference between both structures is that Elfxx_Rela contains one additional field dedicated as a relocation addend.
It is important to note that these relocation entry types are mutually exclusive within the context of a given ELF object. This means that if one type of entry is used, the other one will not be used consequently.
The reason for using one type of entry over the other, is usually architecture dependant.
For example, in x86 only Elf32_Rel is used, while on x86_64 only Elf64_Rela is used. However this is not always valid for every architecture, for instance, SPARC always uses some instance of Elfxx_Rela.
The different fields in these structures are the following:
- r_offset: This field holds the location where a particular relocation has to take place, however it may have different interpretations depending on ELF object type.
- For ET_REL type binaries, this value denotes an offset within a section header. in which the relocations have to take place
- For ET_EXEC type binaries, this value denotes a virtual address affected by a relocation
- r_info: This field denotes both the symbol index within a symbol table of the correspondent symbol that has to be relocated, as well as the relocation type for that specific symbol. Both of these pieces of information can be retrieved from this field using the following macros:
- ELF32_R_SYM(info) ((info)>>8)
- ELF32_R_TYPE(info) ((unsigned char)(info))
- ELF64_R_SYM(info) ((info)>>32)
- ELF64_R_TYPE(info) ((Elf64_Word)(info))
- r_addend: This field specifies a constant addend to be added to compute the value to be stored in a given relocation reference.
These relocation entries are always found in some relocation section. Every relocation section may reference two additional sections.
- A relocation section will always be linked to its correspondent symbol table. This symbol table can be located as a section in the Section Header Table, and its index can be retrieved by the sh_link field of the relocation section’s Elfxx_Shdr instance.
- As previously mentioned, if a file is of type ET_REL, a given relocation entry’s r_offset will be an offset to a particular ELF section where a relocation has to take place. The section index where to apply that offset can be retrieved by the relocation section’s Elfxx_Shdr sh_info field.
The following diagram illustrates the previous relationships of the relocation section.

Figure 3 : Section relationships involved in relocation entries.
The diagram above is a generic representation of the relationship between the different data structures involved in relocations. As mentioned before, the relocation section is linked to two other sections. One of them is the symbol table, where the symbols that will be relocated are held. In this case, the section is the .dynsym section, the symbol table that holds symbols for Dynamic Linking.
The additional section linked to the relocation section is where the relocations are going to take place. In this case, the section is the .got.plt section, which is a specific section dedicated to hold a table of pointers, as an interface for the application to access relocated dynamically linked procedures addresses. This table of pointers is also known as the Global Offset Table (GOT). We will discuss the exact usage and mechanisms involved with this section in the next post.
3. Relocation types
As mentioned before, the r_info field of Elfxx_Rel and Elfxx_Rela contains two encoded values, which are the symbol index where the relocation is being applied to and the relocation type to apply accordingly. There are various relocations types and usually, these relocation types are architecture dependant. In this post, we cover relocation types of x86 and x86_64, but it is advised to rely on the ELF documentation of a given architecture to know its specific relocation types.
The difference between relocation types resides in the way the relocated value is calculated.
There are different variables that can potentially be involved in the calculation process. These variables are:
- A: Addend of Elfxx_Rela entries.
- B: Image base where the shared object was loaded in process virtual address space.
- G: Offset to the GOT relative to the address of the correspondent relocation
entry’s symbol. - GOT: Address of the Global Offset Table
- L: Section offset or address of the procedure linkage table (PLT, .got.plt).
- P: The section offset or address of the storage unit being relocated.
retrieved via r_offset relocation entry’s field. - S: Relocation entry’s correspondent symbol value.
- Z: Size of Relocations entry’s symbol.
Usually the relocation type name is descriptible enough to interpret its needed calculation. The following list presents the most common suffix names and their meaning for different relocation types in x86 and x86_64:
Generic relocation suffixes:
- *_NONE: Neglected entry.
- *_64: qword relocation value.
- *_32: dword relocation value.
- *_16: word relocation value.
- *_8: byte relocation value.
- *_PC: relative to program counter.
- *_GOT: relative to GOT.
- *_PLT: relative to PLT (Procedure Linkage Table).
- *_COPY: value copied directly from shared object at load-time.
- *_GLOB_DAT: global variable.
- *_JMP_SLOT: PLT entry.
- *_RELATIVE: relative to image base of program’s image.
- *_GOTOFF: absolute address within GOT.
- *_GOTPC: program counter relative GOT offset.
This being said, in the following tables x86 and x86_64 relocation types and their correspondent calculations are defined:
x86 Relocation types
| Name | Value | Field | Calculation |
|---|---|---|---|
| R_386_NONE | 0 | None | None |
| R_386_32 | 2 | dword | S + A |
| R_386_PC32 | 1 | dword | S + A - P |
| R_386_GOT32 | 3 | dword | G + A |
| R_386_PLT32 | 4 | dword | L + A - P |
| R_386_COPY | 5 | None | Value is copied directly from shared object |
| R_386_GLOB_DAT | 6 | dword | S |
| R_386_JMP_SLOT | 7 | dword | S |
| R_386_RELATIVE | 8 | dword | B + A |
| R_386_GOTOFF | 9 | dword | S + A - GOT |
| R_386_GOTPC | 10 | dword | GOT + A - P |
| R_386_32PLT | 11 | dword | L + A |
| R_386_16 | 20 | word | S + A |
| R_386_PC16 | 21 | word | S + A - P |
| R_386_8 | 22 | byte | S + A |
| R_386_PC8 | 23 | byte | S + A - P |
| R_386_SIZE32 | 38 | dword | z + A |
x86_64 Relocation types
| Name | Value | Field | Calculation |
|---|---|---|---|
| R_X86_64_NONE | 0 | None | None |
| R_X86_64_64 | 1 | qword | S + A |
| R_X86_64_PC32 | 2 | dword | S + A - P |
| R_X86_64_GOT32 | 3 | dword | G + A |
| R_X86_64_PLT32 | 4 | dword | L + A - P |
| R_X86_64_COPY | 5 | None | Value is copied directly from shared object |
| R_X86_64_GLOB_DAT | 6 | qword | S |
| R_X86_64_JUMP_SLOT | 7 | qword | S |
| R_X86_64_RELATIVE | 8 | qword | B + A |
| R_X86_64_GOTPCREL | 9 | dword | G + GOT + A - P |
| R_X86_64_32 | 10 | dword | S + A |
| R_X86_64_32S | 11 | dword | S + A |
| R_X86_64_16 | 12 | word | S + A |
| R_X86_64_PC16 | 13 | word | S + A - P |
| R_X86_64_8 | 14 | word8 | S + A |
| R_X86_64_PC8 | 15 | word8 | S + A - P |
| R_X86_64_PC64 | 24 | qword | S + A - P |
| R_X86_64_GOTOFF64 | 25 | qword | S + A - GOT |
| R_X86_64_GOTPC32 | 26 | dword | GOT + A - P |
| R_X86_64_SIZE32 | 32 | dword | Z + A |
| R_X86_64_SIZE64 | 33 | qword | Z + A |
Next Up: Dynamic Linking
In this post we covered ELF relocations and their different types and calculations. We also described how relocations and symbols are linked together, among other data structures involved in relocations. In the next post, we will revisit dynamic linking, and cover it in greater depth.
Intezer
Count on Intezer AI SOC to triage, investigate and respond to every alert at unmatched speed and accuracy.
In this article
Share article
Executable and Linkable Format 101 Part 3: Relocations
.png)
AI SOC
AI
Company News
5 minutes
Loop engineering comes to the SOC: Introducing the Intezer Org Brain
Organizational context in an AI SOC is table stakes. Org Brain is very different. It learns, it recalls, it fetches what it's missing, and it gets sharper with every alert it touches, all autonomously.

Detection Engineering
AI SOC
8 minutes
Detection engineering in the AI era
AI is lowering the barrier to sophisticated attacks. Explore why detection engineering matters and where most programs fall short.

AI SOC
CISO
Company News
Introducing Custom Agents: Automate your SOC, your way
Add your own agents and automations on top of the ones Intezer runs out of the box, take more of the manual work off your analysts, and tailor AI SOC to the way your team actually operates.